node.js基础模块http、网页分析工具cherrio实现爬虫
一、前言
说是爬虫初探,其实并没有用到爬虫相关第三方类库,主要用了node.js基础模块http、网页分析工具cherrio。 使用http直接获取url路径对应网页资源,然后使用cherrio分析。 这里我主要学习过的案例自己敲了一遍,加深理解。在coding的过程中,我第一次把jq获取后的对象直接用forEach遍历,直接报错,是因为jq没有对应的这个方法,只有js数组可以调用。
二、知识点
①:superagent抓去网页工具。我暂时未用到。
②:cherrio 网页分析工具,你可以理解其为服务端的jQuery,因为语法都一样。
效果图
1、抓取整个网页
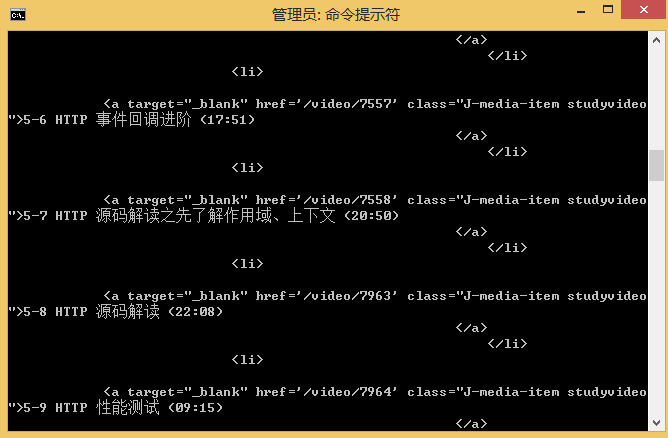
2、分析后的数据,提供的示例为案例实现的例子。
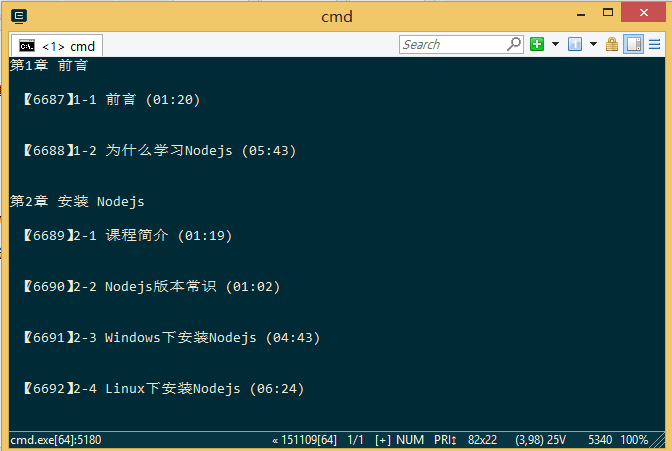
爬虫初探源码分析
var http=require('http');
var cheerio=require('cheerio');
var url='http://www.imooc.com/learn/348';
/****************************
打印得到的数据结构
[{
chapterTitle:'',
videos:[{
title:'',
id:''
}]
}]
********************************/
function printCourseInfo(courseData){
courseData.forEach(function(item){
var chapterTitle=item.chapterTitle;
console.log(chapterTitle+'n');
item.videos.forEach(function(video){
console.log(' 【'+video.id+'】'+video.title+'n');
})
});
}
/*************
分析从网页里抓取到的数据
**************/
function filterChapter(html){
var courseData=[];
var $=cheerio.load(html);
var chapters=$('.chapter');
chapters.each(function(item){
var chapter=$(this);
var chapterTitle=chapter.find('strong').text(); //找到章节标题
var videos=chapter.find('.video').children('li');
var chapterData={
chapterTitle:chapterTitle,
videos:[]
};
videos.each(function(item){
var video=$(this).find('.studyvideo');
var title=video.text();
var id=video.attr('href').split('/video')[1];
chapterData.videos.push({
title:title,
id:id
})
})
courseData.push(chapterData);
});
return courseData;
}
http.get(url,function(res){
var html='';
res.on('data',function(data){
html+=data;
})
res.on('end',function(){
var courseData=filterChapter(html);
printCourseInfo(courseData);
})
}).on('error',function(){
console.log('获取课程数据出错');
})
参考资料:
https://github.com/alsotang/node-lessons/tree/master/lesson3
http://www.imooc.com/video/7965
Node.js项目中调用JavaScript的EJS模板库的方法
作为外部模块,调用的方法和mysql模块是相同的,不再赘述。ejs的render函数有两个参数第一个是字符串,第二个是可选的对象,和其他javascript模版一样
Node.js的Express框架使用上手指南
Express介绍npm提供了大量的第三方模块,其中不乏许多Web框架,比如我们本章节要讲述的一个轻量级的Web框架———Express。Express是一个简洁、灵活的node.
Node.js编写爬虫的基本思路及抓取百度图片的实例分享
其实写爬虫的思路十分简单:按照一定的规律发送HTTP请求获得页面HTML源码(必要时需要加上一定的HTTP头信息,比如cookie或referer之类)利用正则匹配或
